
March 2022
For this project you have to deploy a very recent OCR engine and expose its service as a REST API. You will also have to set up a task queue to manage several workers, and cope with long-running tasks. We will reach Docker’s limit here as we will run all our workers on a single machine, while it would make sense, at this point, to scale out, i.e. run workers on different machines. Going further would require some Docker Swarm, or Kubernetes, skills, and is the work of DevOps you should be able to talk to, at this point.
Please enjoy this great component diagram to illustrate our architecture design:
We split the project into 4 stages, and you must complete them all to get the maximal grade. These stages are build each on top of the other, progressively increasing the difficulty, so start with stage 1.
What you will have to do:
Dockerfiles and docker-compose.yaml files, as instructed.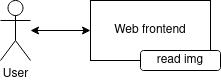
Using the files provided in the resources/stage1 folder, create a mock web service (Flask application) which:
/imgshape routeYou will need to:
resources/stage1/OCR_route.py file.requirements.txt file.Dockerfile file.docker-compose.yaml file.solution/stage1/Dockerfile: the description of the steps required to build the image containing your applicationsolution/stage1/docker-compose.yaml: a file which enables anyone to run your service using docker-compose upsolution/stage1/sources/*: all the files needed to build and run a container with your application5000 on the host machine.Connectivity check
$ curl --url http://localhost:5000/
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<title>404 Not Found</title>
<h1>Not Found</h1>
<p>The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.</p>Correct usage
$ curl -X POST --header "Content-type: image/jpeg" --url http://localhost:5000/imgshape -T testimage.jpg
{
"content": {
"depth": 3,
"height": 500,
"width": 500
}
}Wrong HTTP method
$ curl -X GET --url http://localhost:5000/imgshape
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<title>405 Method Not Allowed</title>
<h1>Method Not Allowed</h1>
<p>The method is not allowed for the requested URL.</p>Submit bad file
$ curl -X POST --header "Content-type: image/jpeg" --url http://localhost:5000/imgshape -T requirements.txt # any buggy file
{
"error": "Cannot open image."
}requirements.txt.libglib2.0-0 on Debian-based images.OCR_route.py file, they contain all the functions we used.requirements.txt is present and correctDockerfilerequirements.txt and Dockerfile image and packagesDockerfile or docker-compose.yamldocker-compose.yaml which runs a working server, correctly listening in port 5000 on the host, when running docker-compose upTotal for stage 1: 9 points
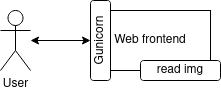
Flask is not ready for production, i.e. it cannot handle efficiently and safely an important number of connections. We will add a production-ready Python WSGI HTTP server, Gunicorn, to our image.
This server will have exactly the same features as the one from stage 1, but will listen on port 8000 (more common for Python servers).
You will need to:
Gunicorn.Dockerfile and/or docker-compose.yaml to update the launch command.Same as stage 1, but organized under a solutions/stage2/ directory.
Same as stage 1, but with connection to port 8000 instead of 5000.
Dockerfile and docker-compose.yaml which runs a working server, correctly listening in port 8000 on the host, when running docker-compose upTotal for stage 2: 2 points
Total so far: 11 points
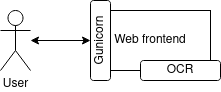
This is a tricky part as the OCR we want to deploy requires a super-heavy image. However, it is pretty easy to install: you can install it directly from the GitHub repo using pip. Warning: if you plan to test it on your computer, make sure you have at least 10 GB of free space and at least 4 GB of free RAM.
You will need to:
pero_ocr_driver.py file in your project.Dockerfile to install the Python package at https://github.com/jchazalon/pero-ocr/archive/refs/heads/master.zip and its dependencies. pip should do it automatically.OCR_route.py file to call the OCR using the code provided below.Dockerfile to install the content of https://www.lrde.epita.fr/~jchazalo/SHARE/pero_eu_cz_print_newspapers_2020-10-09.tar.gz under some well-defined path in your image.ParseNet.pbcheckpoint_350000.pthconfig.iniocr_engine.json/ocr route on the web server which will accept images and return their transcription./root/.cache/torch/hub/checkpoints/vgg16-397923af.pth in your image, or any appropriate place if you set up users, to avoid re-downloading VGG16 weights each time you run your container.Code to launch the OCR
from pero_ocr_driver import PERO_driver
# TODO reuse previous code from the /imgshape/ route to read the image content
# `img` should be a valid numpy array representing an image in what follows
# Init the OCR engine if needed
start_time = time.time()
ocr_engine = PERO_driver(os.environ['PERO_CONFIG_DIR'])
elapsed_time = int((time.time() - start_time) * 1000)
print("init 'pero ocr engine' performed in %.1f ms.", elapsed_time)
# Perform the actual computation
ocr_results = ocr_engine.detect_and_recognize(img)
ocr_results = "\n".join([textline.transcription for textline in ocr_results])
print(ocr_results)
# TODO return result as json payloadSame as stage 1, but organized under a solutions/stage3/ directory.
8000 on the host machine.Check running
$ curl --url http://localhost:8000/check
HelloCheck OCR service
$ curl -X POST --header "Content-type: image/jpeg" --url http://localhost:8000/ocr -T text2.jpg | jq .content
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 22051 100 340 100 21711 57 3657 0:00:05 0:00:05 --:--:-- 71
"Goujet, Cordeliers, 7.\nGoupil, spécialité pour la fonderie\nde caractères, rabotte toutes\nsortes de métaux, fait les prèces\ndétachées, Monsieur-le-Prince,\n20."OCR_route.pyTotal for stage 3: 5 points
Total so far: 16 points
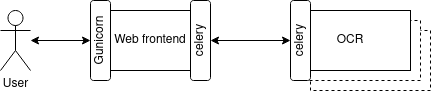
Here we are getting serious. This is actually the step which motivated us to propose this project. The trouble with the previous stage is that requests to the web server trigger a long-running and CPU-bounded computation on the server, eventually freezing the web server, or even leading to HTTP timeouts.
We will use Celery to decouple the web frontend from the OCR worker(s). In this project we will use only one OCR worker, but the idea is that this can scale out (be distributed to multiple computers) quite easily once this is done. This will require setting up two images: 1 for the web frontend (super light) and 1 for the OCR worker (super heavy).
This works as follows:
The new web frontend will contain the following routes: - GET /check: simply answers “Hello” to check for a working server - POST /ocr enqueues a task with the image submitted and return the task id - GET /results/<task_id>: returns the status of the task with the given id, and the result if it is available.
You will need to:
resources/stage4/web/OCR_route.py for the web component.resources/stage4/ocr/*.py for the OCR component.Dockerfile for each component.docker-compose.yaml.Same as stage 1, but organized under a solutions/stage4/ directory.
8000 on the host machine.Check running
$ curl --url http://localhost:8000/check
HelloCheck OCR service
$ curl -X POST --header "Content-type: image/jpeg" --url http://localhost:8000/ocr -T text2.jpg
{
"submitted": "8404359a-6b2f-4ae1-a479-66d1fc09819b"
}
$ sleep 10
$ curl --url http://localhost:8000/results/8404359a-6b2f-4ae1-a479-66d1fc09819b
{
"content": {
"content": "Goujet, Cordeliers, 7.\nGoupil, sp\u00e9cialit\u00e9 pour la fonderie\nde caract\u00e8res, rabotte toutes\nsortes de m\u00e9taux, fait les pr\u00e8ces\nd\u00e9tach\u00e9es, Monsieur-le-Prince,\n20."
}
}Start by getting the simple mock server to work with the Celery setup.
Run the OCR using the following command:
celery --app=worker.celery worker --concurrency=1 -P threads --loglevel=INFOThe RabbitMQ image comes with default user and password when none is configured: guest:guest, so you can use the following URI for your Celery broker: amqp://guest:guest@rabbitmq:5672 (provided you named the Rabbit MQ service rabbitmq).
You can use the default rpc:// backend for Celery results.
Your docker-compose.yaml will contain 3 services: ocr, web and rabbitmq.
Dockerfile for web componentDockerfile for OCR componentdocker-compose.yaml which runs a working server, correctly listening in port 8000 on the host, when running docker-compose upTotal for stage 4: 4 points
Total so far: 20 points
If you want to make money.
You MUST submit your project using Moodle.
Your submission MUST be a compressed archive (.tar.gz) containing the following files:
solutions/stage1/Dockerfilesolutions/stage1/docker-compose.yamlsolutions/stage1/sources/OCR_routes.pysolutions/stage1/sources/requirements.txtsolutions/stage2/Dockerfilesolutions/stage2/docker-compose.yamlsolutions/stage2/sources/OCR_routes.pysolutions/stage2/sources/requirements.txtsolutions/stage3/Dockerfilesolutions/stage3/docker-compose.yamlsolutions/stage3/sources/OCR_routes.pysolutions/stage3/sources/pero_ocr_driver.pysolutions/stage3/sources/requirements.txtsolutions/stage4/Dockerfile-ocrsolutions/stage4/Dockerfile-websolutions/stage4/docker-compose.yamlsolutions/stage4/sources-ocr/pero_ocr_driver.pysolutions/stage4/sources-ocr/requirements.txtsolutions/stage4/sources-ocr/celeryconfig.pysolutions/stage4/sources-ocr/worker.pysolutions/stage4/sources-web/requirements.txtsolutions/stage4/sources-web/OCR_routes.pyDo not put the test resources (images) in the archive!
Good luck.