Soit $E$ l'erreur du réseau par rapport à la vérité terrain $\bf t$.
Pour corriger l'erreur on modifie les poids $w_{ij}$ du réseau donc on veut évaluer la contribution de chaque poids à l'erreur c.a.d. $ \displaystyle \frac{\partial E}{\partial w_{ij}}$ pour tout $i, j$. Le vecteur composé de l'ensemble de ces dérivées paritelles est le gradiant de E, noté $\nabla E$.
Comme $$ \frac{\partial E}{\partial w_{ij}} = \frac{\partial E}{\partial y} \; \frac{\partial y}{\partial w_{ij}} $$
on peut remonter de fil en aiguille pour avoir l'erreur due à un poids loin en amont.
En choisissant comme fonction d'activation une sigmoïde et une erreur quadratique, on a :
$$ \begin{align} \frac{\partial E}{\partial w^2_{0,0}} &= \frac{\partial E}{\partial y} \; \frac{\partial y}{\partial z} \; \frac{\partial z}{\partial y^2_0} \; \frac{\partial y^2_0}{\partial z^2_0} \; \frac{\partial z^2_0}{\partial w^2_{0,0}} \\ &= 2\, (y-t)\; y\,(1-y)\; w^3_0 \; y^2_0 (1-y^2_0) \; y^1_0 \end{align} $$On corrige les poids en remontant le gradient d'erreur :
$$ \forall \; {\rm layer} \; l \quad {\bf W}^{l} \leftarrow {\bf W}^{l} - \eta \nabla E({\bf W}^{l}) $$ou avec d'autres méthodes plus sophistiquées (qui s'appuie sur ce principe).
import numpy as np
import tensorflow as tf
MY_GPU = 3
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
# Restrict TensorFlow to only use the first GPU
try:
tf.config.experimental.set_visible_devices(gpus[MY_GPU], 'GPU')
tf.config.experimental.set_memory_growth(gpus[MY_GPU], True)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPU")
except RuntimeError as e:
# Visible devices must be set before GPUs have been initialized
print(e)
4 Physical GPUs, 1 Logical GPU
TensorFlow permet de caluler les dérivées partielle explicitement en un point $x$ donné. Ici on veut calculer $\displaystyle \frac{\partial z}{\partial x}(3)$ avec
x = tf.Variable(3.)
with tf.GradientTape() as tape:
y = x**2
z = y**2
dz_dx = tape.gradient(z,x)
print(dz_dx.numpy())
108.0
$\displaystyle \frac{\partial z}{\partial x}= \frac{\partial z}{\partial y} \frac{\partial y}{\partial x} = 2 \, y \; 2\, x = 2 \, x^2 \; 2 \, x = 4 \, x^3$ ce qui est donne bien 108 pour $x = 3$.
inputs = tf.keras.Input(shape=[2])
hidden = tf.keras.layers.Dense(3, activation="sigmoid")(inputs)
last = tf.keras.layers.Dense(1, activation="sigmoid")(hidden)
model = tf.keras.Model(inputs=inputs, outputs=last)
model.summary()
Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 2)] 0 _________________________________________________________________ dense (Dense) (None, 3) 9 _________________________________________________________________ dense_1 (Dense) (None, 1) 4 ================================================================= Total params: 13 Trainable params: 13 Non-trainable params: 0 _________________________________________________________________
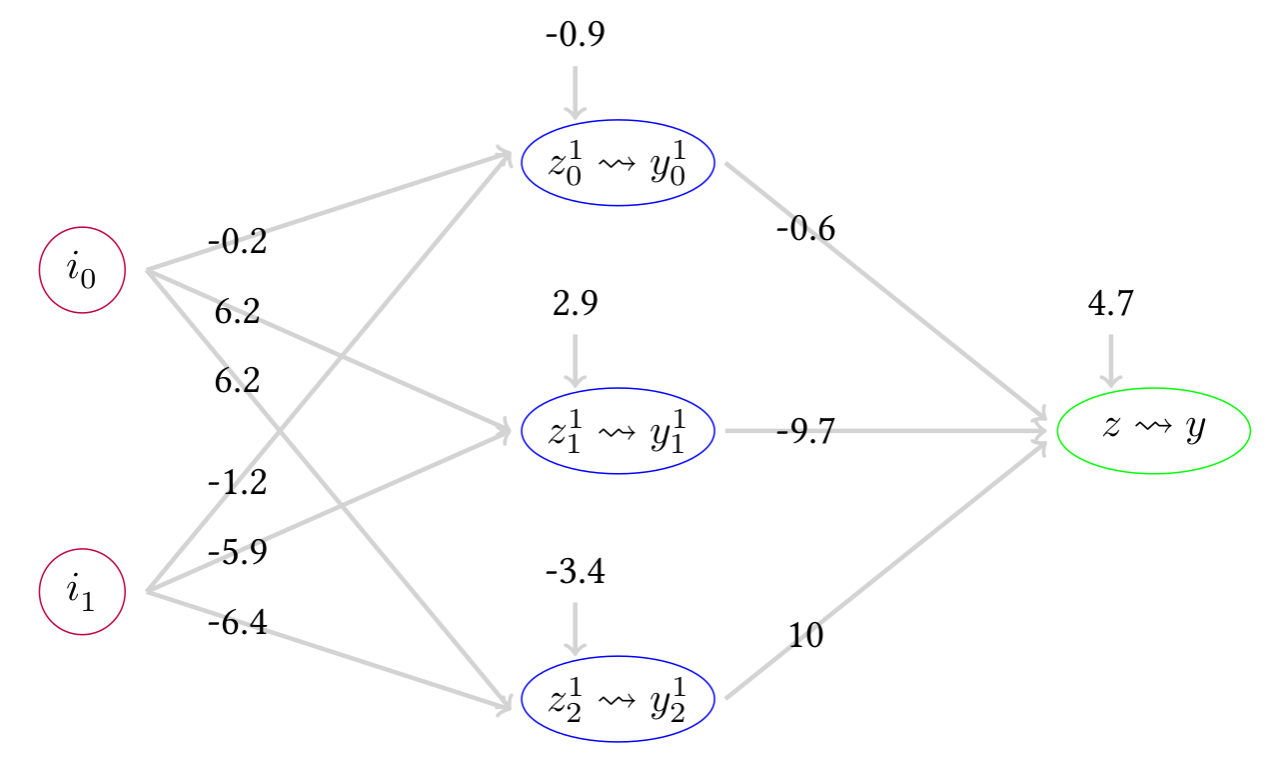
# Je rentre les poids à main pour avoir la même chose que sur le dessin
w = [ np.array([[-0.2, 6.2, 6.2], [-1.2, -5.9, -6.4]]),
np.array([-0.9, 2.9, -3.4]),
np.array([[-0.6], [-9.7], [10.]]),
np.array([4.7]) ]
model.set_weights(w)
model.predict([[1,1]]) # je teste
array([[0.01202349]], dtype=float32)
# je teste autrement et je calcule l'erreur quadratique
x = tf.constant([[1.,0.]])
y = model(x)
loss = tf.reduce_mean((1 - y)**2)
print(f"y: {y}\nLoss: {loss}")
y: [[0.9863194]] Loss: 0.0001871581916930154
# Je peux calculer l'erreur pour tout poids du réseau avec GradientTape
with tf.GradientTape() as tape:
y = model(x)
loss = tf.reduce_mean((1 - y)**2)
grad = tape.gradient(loss, model.trainable_variables)
print(f"y: {y}\n\nLoss: {loss}\n\nGrad: {grad}")
y: [[0.9863194]]
Loss: 0.0001871581916930154
Grad: [<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[ 4.1505675e-05, 3.9997175e-07, -1.9950628e-04],
[ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00]], dtype=float32)>, <tf.Tensor: shape=(3,), dtype=float32, numpy=array([ 4.1505675e-05, 3.9997175e-07, -1.9950628e-04], dtype=float32)>, <tf.Tensor: shape=(3, 1), dtype=float32, numpy=
array([[-9.2202856e-05],
[-3.6915427e-04],
[-3.4803167e-04]], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([-0.0003692], dtype=float32)>]
# pour appliquer l'erreur aux poids, je peux le faire à la main comme j'ai changé les valeurs
# ou bien, je choisis un solveur et je lui demande d'appliquer le gradiant de l'erreur des poids
optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
optimizer.apply_gradients(zip(grad, model.variables))
model.get_weights()
[array([[-0.20018585, 6.1999774 , 6.2001967 ],
[-1.2 , -5.9 , -6.4 ]], dtype=float32),
array([-0.9001858, 2.8999777, -3.3998032], dtype=float32),
array([[-0.59980667],
[-9.699801 ],
[10.000198 ]], dtype=float32),
array([4.700198], dtype=float32)]
La fonction apply_gradients permet de choisir les poids mis à jour. Cela permet de ne mettre à jour
qu'une partie du réseau. Ainsi si votre réseau est composé de sous-réseaux, vous pouvez calculer
une erreur pour un sous-réseau et ne mettre à jour que ce sous-réseau.